I originally wrote this as a LinkedIn post while exploring parameter-efficient fine-tuning methods. I’m sharing it here for reference and plan to revisit this topic with a deeper, more detailed blog post in the future.
Over the past few months, during my research in Machine Learning and Security, I kept running into the term LoRA (Low Rank Adaptation).
At first, I brushed it off as just another term and only looked at the high-level idea. But as I started reading more papers and designing my own experiments, I realised how important this concept actually is, which pushed me to take a deeper look.
Here is the basic intuition.
Most modern models begin with pretraining. A large model is trained on massive and diverse data, like large parts of the internet or huge image datasets, to learn general patterns. This pretrained model then acts as a base model.
To adapt this base model to a specific task, we usually rely on fine-tuning. Fine-tuning means updating all the model’s weights using task-specific data. While this works well, it comes with some clear drawbacks:
- Updating all weights requires massive GPU memory and storage
- Fine-tuning for every new task means repeating the entire expensive process
This is where LoRA becomes especially useful. Instead of modifying the entire weight matrix, LoRA adds a small, trainable update to it. Conceptually, this looks like:
W_new = W + ΔW
ΔW = A · B
Here, A and B are low-rank matrices added to a specific layer. During training, only these matrices are updated, while the original weights remain frozen. During inference, the layer simply uses the combined weights (W_new).
Why is this useful?
- We only train a small number of parameters, making training far more efficient
- For a new task, we can swap out A · B with another set for that task, without touching the base model
This makes adapting large models significantly cheaper and more scalable.
This is just a short summary, but understanding LoRA and the ideas that came before it really changed how I think about model adaptation.
To know more about the prior work and why it works, do refer to the original LoRA paper from Microsoft Research!
Below is an image I took from One Minute NLP.
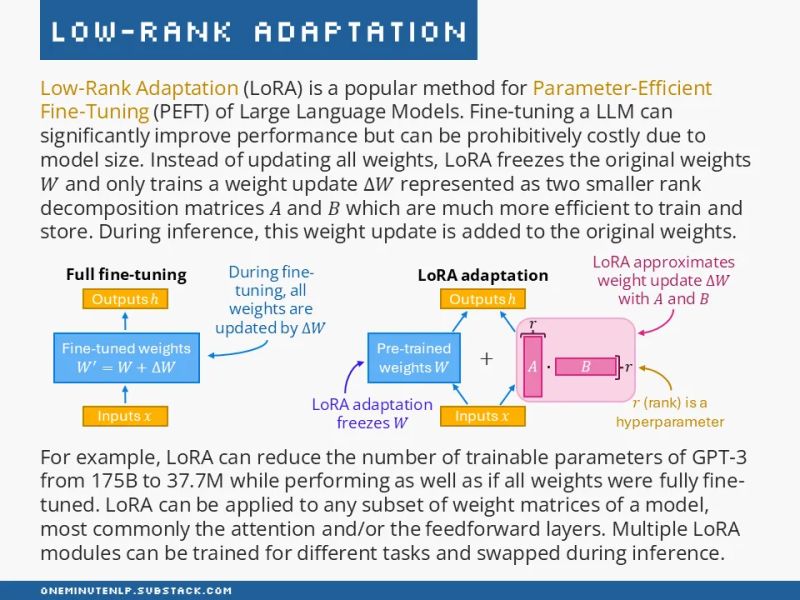 Source: One Minute NLP - LoRA visualisation
Source: One Minute NLP - LoRA visualisation
Thanks for reading!